Карта развития дата-сайентиста: с чего начать, к чему идти и сколько времени потребуется
Содержание:
- Введение
- Изучаем по необходимости, этапы 2-5
- Как я сменил несколько профессий и остановился на Data Science
- Что мне нравится в моей работе
- Инструменты
- Data Scientist: кто это и что он делает
- Большие данные
- Образование в области Data Science: ничего невозможного нет
- Что знают и умеют дата-сайентисты
- Хорошие конференции и митапы
- Что такое Data Science?
- Полный курс по Data Science
Введение
Привет, я хочу рассказать вам, как стать Data Scientist, не имея диплома (или просто бесплатно). По иронии судьбы, у меня есть диплом, и он даже имеет отношение к Data Science (Магистерская программа в Северо-Западном университете). Но до этого я работал бухгалтером в Deloitte. Странно, да? Я был далек от Data Science и всего технического. Мне приходилось много изучать онлайн самостоятельно после работы и даже во время магистратуры, чтобы догнать однокурсников, так как я пришел не из технической сферы. Как человек, прошедший через все это, могу с уверенностью сказать, что обучение в университете очень помогает, но совсем не обязательно. Мне кажется, раз я побывал по обе стороны — и диплом получил, и онлайн учился — я смогу дать вам особый взгляд. Получение магистерской степени в Data Science — хороший и быстрый способ попасть в эту сферу, но, к счастью, вовсе не единственный, особенно, если вы не хотите тратить $60–90 тысяч на обучение. Однако от вас потребуется строгая самодисциплина.
Если кто-то спросит меня, как попасть в Data Science, этот пост будет для них. Надеюсь, что мои советы будут актуальны и полезны; во время моего обучения мне очень помогали эти ресурсы. Прежде, чем мы углубимся в детали, давайте разберемся, что такое Data Science.
Изучаем по необходимости, этапы 2-5
Визуализация данных
В какой-то момент времени вам потребуется уметь визуализировать данные, с которыми вы работаете. Имеет смысл активно это изучать тогда, когда вы будуте готовы сразу примененять эти знаний на практике, потому что иначе они не запоминаются. В Питоне существует несколько библиотек (привожу рекомендуемый порядок изучения):
-
matplotlib – на нём базируется следующие два варианта, и потенциально он может всё. Но тяжел и неэффективен для прямого использования, кроме построения уродливых графиков, для себя и коллег-технарей. Можно специально не учиться его применять, а понять только самые основы, которые будут «проступать» из-за других библиотек.
-
seaborn — очень популярная библиотеа, в одну строчку решающая многие стандартные задачи. Достаточно понимать принципы и уметь находить как сделать нужные вещи с помощью документации.
-
plotnine — позволяет создавать очень креативные графики. Супер-мощный инструмент, позволяющий в несколько строчек кода создать самые нетривиальные графики. В сравнении — seaborn не имеет подобной гибкости, а в matplotlib замучаешься разбираться чтобы сделать такой же график, если он не совсем примитивный. Однако, поначалу, plotnine требует определенного времени на освоение. Если бы не существовал plotly — это был бы самый мощный инструмент.
-
plotly — позволяет делать все графики интерактивными. Сложен в изучении и плохо документирован. Вероятно, не имеет смысл его изучать, пока вы не поймёте точно что вам это необходимо (интерактивность).
До начала применения в реальной практике, на обучение можно себя ограничить в 10-20ч на одну библиотеку.
Если вам нет нужды сначала применять питон для подготовки данных, или вы хотите создать визуальные дэшборды которыми смогут пользоваться другие люди — посмотрите в сторону PowerBI и Tableau, это крайне мощные и популярные инструменты визуализации данных. Изучить каждый из этих инструментов на минимальном рабочем уровне можно, примерно, за 60ч. Знание связки SQL+Excel+PowerBI/Tableau откроет вам позиции аналитиков и «BI-специалистов» c окладами в Москве от 100 тыс., коммуникабельные специалисты с хорошими знаниями этих инструментов находят позиции с ЗП от 150 тыс. Подобные вакансии в основном встречаются в корпорациях и системных интеграторах.
Средства работы с данными
Можно учить на разных этапах, в зависимости от задач, с которыми столкнётесь
-
Основы regular expressions, aka RegExp (10ч). Знания regexp необходимо для продвинутой фильтрации данных в разных инструментах для работы с данными.
-
PySpark (40ч на изучение основ, 100-200ч на достижение хорошего рабочего навыка) . Он необходим когда у вас данных очень много, и приходиться обрабатывать их сразу на целой группе серверов (кластере). Это уже Big data. Не имеет смысл разбираться с ним заранее, т.к. знания являются не фундаментальными и легко забываются. Эффективнее осваивать когда планируете начать использовать (или перед тем как подать резюме на позицию, требующую данных знаний).
Внутри Spark устроен сильно не так, как обычные базы данных, но с точки зрения использования он оказывается сильно похожим, т.к. поддерживает почти стандартный SQL синтаксис или, как альтернативу, API отдалённо похожий на pandas. Определенные концептуальные отличия присутствуют, но больших сложностей в освоении это не вызывает. В последнее время продвигают библиотеку Koalas, которая будет использовать команды совсем как у pandas для работы с spark-кластером, но пока не советую делать это основным подходом по работе с Spark.
-
Основы html — необходимы, как минимум, для общения с коллегами и понимания их языка, если вы хоть немного сталкиваетесь с сайтами и необходимостюь их парсить или анализировать данные с них.
Как я сменил несколько профессий и остановился на Data Science
Я учился в Московском авиационно-технологическом институте на «Проектировании и технологии электронных средств». Должен был разрабатывать электронику, но заинтересовался программированием. Спасибо моему преподавателю, который привил интерес к этому делу.
С нашей кафедрой сотрудничала фирма, в которую выпускникам можно было устроиться на практику или работу, поэтому с третьего курса я уже подрабатывал. В IT-сфере я сменил много профессий: был техническим писателем, разработчиком сайта, аналитиком, год в стартапе работал менеджером продукта — мы делали медицинский браслет для пожилых людей.
Пока работал на разных должностях, понял, что у меня исследовательский склад мышления и характера. В программировании, чтобы получить наибольшую выгоду, нужно решать задачи определенным образом, точно знать, какой инструмент уместнее применить. Мне же было интересно что-то новое, неизведанное, работа с неполными данными. Data Science тогда как раз развивался, поэтому я пошел учиться на это направление.
За восемь месяцев учебы ты не станешь синьором, скорее сформируешь терминологический аппарат, поймешь, как правильно гуглить вопросы. Учеба расширяет кругозор, это важнее. Однажды на проекте по классификации комментариев я смог показать качество, сравнимое с крупным подрядчиком. Я затратил минимум ресурсов компании, используя только знания о продукте. Я понял, что можно взять почти готовую библиотеку, запустить ее и получить неожиданные классные результаты.
Что мне нравится в моей работе
Я работаю в «Тинькофф» уже три с половиной года. В нашей компании много задач для сайентистов и почти нет ограничений по развитию. Наука о данных — достаточно универсальная область
По сути тебе не важно какими данными ты занимаешься: о торговле продуктами или о поведении пользователей в интернете. Для всех задач есть одинаковая база: математика и программирование
Зная базовые вещи уже можно углубляться в конкретные области, например, компьютерное зрение или обработку естественного языка.
Большинство задач в индустрии довольно стандартные, они ориентированы прежде всего на бизнес-результат. Поэтому в какой-то момент каждому специалисту хочется начать делать что-то свое параллельно основной работе. Я, например, хотел бы привнести что-то новое в open-source (программы и технологии для разработчиков), но пока своих значимых кейсов нет.
Мне нравится создавать технологии, которые автоматизируют ручную работу. Например, известная в машинном обучении библиотека scikit-learn поделила профессию на «до» и «после»: у разработчиков появились инструменты для быстрой работы с алгоритмами ML.
Еще мне хотелось бы углубиться в другие области машинного обучения. Я занимаюсь временными рядами, обычно в этой специализации лучше работают классические модели. И хочу поглубже копнуть в Deep Learning — глубинное обучение, где нейросети способны решать очень сложные задачи. Именно в этой области сейчас происходят наиболее интересные в машинном обучении вещи.
Курс
Полный курс по Data Science
Освойте востребованную профессию с нуля за 12 месяцев и станьте уверенным junior-специалистом.
- Индивидуальная поддержка менторов
- 10 проектов в портфолио
- Помощь в трудоустройстве
Получить скидку Промокод “BLOG10” +5% скидки
Инструменты
Python. Популярный высокоуровневый язык программирования
Pandas. Популярная и быстроразвивающаяся библиотека для обработки и анализа данных в Python
PostgreSQL. База данных с открытым исходным кодом, на основе которой функционируют многие приложения
Apache Spark. Фреймворк для реализации распределенной обработки неструктурированных данных
OpenCV. Библиотека алгоритмов компьютерного зрения
R. Язык программирования для статистической обработки данных
Hadoop. Программный каркас, который помогает обрабатывать и хранить массивы информации
Matplotlib. Библиотека на языке Python для построения научных графиков
Чарльз Делекторских
Fullstack-разработчик
Как правило, специалист Data Scientist работает в большой компании. Крупные работодатели часто принимают к себе новичков, но если у человека совсем нет опыта, то нужно понимать, что в первые месяцы это будет работа на невысокой позиции (возможно, даже в качестве стажера или помощника) с соответствующей зарплатой.
По мере наработке опыта и овладения новыми технологиями растет востребованность Data Scientist, как специалиста. Через несколько лет после начала карьеры, если человек успешно трудится, занимается саморазвитием, повышением квалификации и знает английский язык хотя бы на среднем уровне, он может рассчитывать на трудоустройство даже в зарубежную компанию – с соответствующим окладом и возможностями.
— Чарльз Делекторских Fullstack-разработчик
Data Scientist: кто это и что он делает
В переводе с английского Data Scientist – это специалист по данным. Он работает с Big Data или большими массивами данных.
Источники этих сведений зависят от сферы деятельности. Например, в промышленности ими могут быть датчики или измерительные приборы, которые показывают температуру, давление и т. д. В интернет-среде – запросы пользователей, время, проведенное на определенном сайте, количество кликов на иконку с товаром и т. п.
Данные могут быть любыми: как текстовыми документами и таблицами, так и аудио и видеороликами.
От области деятельности зависят и результаты работы Data Scientist. После извлечения нужной информации специалист устанавливает закономерности, подвергает их анализу, делает прогнозы и принимает бизнес-решения.
Человек этой профессии выполняет следующие задачи: оценивает эффективность и работоспособность предприятия, предлагает стратегию и инструменты для улучшения, показывает пути для развития, автоматизирует нудные задачи, помогает сэкономить на расходах и увеличить доход.
Его труд заканчивается созданием модели кода программы, сформировавшейся на основе работы с данными, которая предсказывает самый вероятный результат.
Профессия появилась относительно недавно. Лишь десятилетие назад она была официально зафиксирована. Но уже за такой короткий промежуток времени стала актуальной и очень перспективной.
Каждый год количество информации и данных увеличивается с геометрической прогрессией. В связи с этим информационные массивы уже не получается обрабатывать старыми стандартными средствами статистики. К тому же сведения быстро обновляются и собираются в неоднородном виде, что затрудняет их обработку и анализ.
Вот тут на сцене и появляется Data Scientist. Он является междисциплинарным специалистом, у которого есть знания статистики, системного и бизнес-анализа, математики, экономики и компьютерных систем.
Знать все на уровне профессора не обязательно, а достаточно лишь немного понимать суть этих дисциплин. К тому же в крупных компаниях работают группы таких специалистов, каждый из которых лучше других разбирается в своей области.
Более 100 крутых уроков, тестов и тренажеров для развития мозга
Начать развиваться
Эти знания помогают ему выполнять свои должностные обязанности:
- взаимодействовать с заказчиком: выяснять, что ему нужно, подбирать для него подходящий вариант решения проблемы;
- собирать, обрабатывать, анализировать, изучать, видоизменять Big Data;
- анализировать поведение потребителей;
- составлять отчеты и делать презентации по выполненной работе;
- решать бизнес-задачи и увеличивать прибыль за счет использования данных;
- работать с популярными языками программирования;
- моделировать клиентскую базу;
- заниматься персонализацией продуктов;
- анализировать эффективность деятельности внутренних процессов компании;
- выявлять и предотвращать риски;
- работать со статистическими данными;
- заниматься аналитикой и методами интеллектуального анализа;
- выявлять закономерности, которые помогают организации достигнуть конечной цели;
- программировать и тренировать модели машинного обучения;
внедрять разработанную модель в производство.
Четких границ требований к Data Scientist нет, поэтому работодатели часто ищут сказочное создание, которое может все и на превосходном уровне. Да, есть люди, которые отлично понимают статистику, математику, аналитику, машинное обучение, экономику, программирование. Но таких специалистов крайне мало.
Еще часто Data Scientist путают с аналитиком. Но их задачи несколько разные. Поясню, что такое аналитика и как она отличается от деятельности Data Scientist, на примере и простыми словами.
В банк пришел клиент, чтобы оформить кредит. Программа начинает обрабатывать данные этого человека, выясняет его кредитную историю и анализирует платежеспособность заемщика. А алгоритм, который решает выдавать кредит или нет, – продукт работы Data Scientist.
Аналитик же, который работает в этом банке, не интересуется отдельными клиентами и не создает технические коды и программы. Вместо этого он собирает и изучает сведения обо всех кредитах, что выдал банк за определенный период, например, квартал. И на основе этой статистики решает, увеличить ли объемы выдачи кредитов или, наоборот, сократить.
Аналитик предлагает действия для решения задачи, а Data Scientist создает инструменты.
Большие данные
Начнём с простого — big data, или «большие данные». Это модный термин, обозначающий огромные массивы данных, которые накапливаются в каких-то больших системах.
Например, человек в Москве совершает 5-6 покупок по карте в день, это около 2 тысяч покупок в год. В стране таких людей, допустим, 80 миллионов. За год это 160 миллиардов покупок. Данные об этих покупках — биг дата.
В банках какой-то страны каждый день совершаются сотни тысяч операций: платежи, переводы, возвраты и так далее. Данные о них хранятся в центральном банке страны — это биг дата.
Ещё биг дата: данные о звонках и смс у мобильного оператора; данные о пассажиропотоке на общественном транспорте; связи между людьми в соцсетях, их лайки и предпочтения; посещённые сайты; данные о покупках в конкретном магазине (которые хранятся в их кассе); данные с шагомеров и тайм-трекеров; скачанные приложения; открытые вами файлы и программы… Короче, любой большой массив данных.
Почему появился такой термин: в конце девяностых компании в США стали понимать, что сидят на довольно больших массивах данных, с которыми непонятно что делать. И чем дальше — тем этих данных больше.
Раньше данные были, условно говоря, по кредитным картам, телефонным счетам и из профильных государственных ведомств; а теперь чем дальше — тем больше всего считается. Супермаркеты научились вести сверхточный учёт склада и продаж. Полиция научилась с высокой точностью следить за машинами на дороге. Появились смартфоны, и вообще вся человеческая жизнь стала оцифровываться.
И вот — данные вроде есть, а что с ними делать? Тут на сцену выходит дата-сайенс — дисциплина о больших данных.
Минутка занудства. Все знают, что правильно говорить «биг дэйта», потому что именно так произносят носители языка. Но в русском языке этот термин прижился с побуквенной транслитерацией — как написано, так и читаем. Поэтому — дата. Кстати, с сайентистами такого не произошло — они звучат так же, как в оригинале.
Образование в области Data Science: ничего невозможного нет
Сегодня для тех, кто хочет развиваться в сфере анализа больших данных, существует очень много возможностей: различные образовательные курсы, специализации и программы по data science на любой вкус и кошелек, найти подходящий для себя вариант не составит труда. С моими рекомендациями по курсам можно ознакомиться здесь.
Потому как Data Scientist — это человек, который знает математику. Анализ данных, технологии машинного обучения и Big Data – все эти технологии и области знаний используют базовую математику как свою основу.
Читайте по теме: 100 лучших онлайн-курсов от университетов Лиги плюща Многие считают, что математические дисциплины не особо нужны на практике. Но на самом деле это не так.
Приведу пример из нашего опыта. Мы в E-Contenta занимаемся рекомендательными системами. Программист может знать, что для решения задачи рекомендаций видео можно применить матричные разложения, знать библиотеку для любимого языка программирования, где это матричное разложение реализовано, но совершенно не понимать, как это работает и какие есть ограничения. Это приводит к тому, что метод применяется не оптимальным образом или вообще в тех местах, где он не должен применяться, снижая общее качество работы системы.
Хорошее понимание математических основ этих методов и знание их связи с реальными конкретными алгоритмами позволило бы избежать таких проблем.
Кстати, для обучения на различных профессиональных курсах и программах по Big Data зачастую требуется хорошая математическая подготовка.
«А если я не изучал математику или изучал ее так давно, что уже ничего и не помню»? — спросите вы. «Это вовсе не повод ставить на карьере Data Scientist крест и опускать руки», — отвечу я.

Есть немало вводных курсов и инструментов для новичков, позволяющих освежить или подтянуть знания по одной из вышеперечисленных дисциплин. Например, специально для тех, кто хотел бы приобрести знания математики и алгоритмов или освежить их, мы с коллегами разработали специальный курс GoTo Course. Программа включает в себя базовый курс высшей математики, теории вероятностей, алгоритмов и структур данных — это лекции и семинары от опытных практиков
Особое внимание отведено разборам применения теории в практических задачах из реальной жизни. Курс поможет подготовиться к изучению анализа данных и машинного обучения на продвинутом уровне и решению задач на собеседованиях
|
15 сентября в Москве состоится конференция по большим данным Big Data Conference. В программе — бизнес-кейсы, технические решения и научные достижения лучших специалистов в этой области. Приглашаем всех, кто заинтересован в работе с большими данными и хочет их применять в реальном бизнесе. |
Ну а если вы еще не определились, хотите ли заниматься анализом данных и хотели бы для начала оценить свои перспективы в этой профессии, попробуйте почитать специальную литературу, блоги о науке данных или посмотреть лекции. Например, рекомендую почитать хабы по темам Data Mining и Big Data на Habrahabr. Для тех, кто уже хоть немного в теме, со своей стороны порекомендую книгу «Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных» Петера Флаха — это одна из немногих книг по машинному обучению на русском языке.
Заниматься Data Science так же трудно, как заниматься наукой в целом. В этой профессии нужно уметь строить гипотезы, ставить вопросы и находить ответы на них. Само слово scientist подталкивает к выводу, что такой специалист должен, прежде всего, быть исследователем, человеком с аналитическим складом ума, способный делать обоснованные выводы из огромных массивов информации в достаточно сжатые строки. Скрупулезный, внимательный, точный — чаще всего он одновременно и программист, и математик.
Что знают и умеют дата-сайентисты
Вот начальный список навыков, знаний и умений, которые нужны любому дата-сайентисту для старта в работе.
Математическая логика, линейная алгебра и высшая математика. Без этого не получится построить модель, найти закономерности или предсказать что-то новое.
Есть те, кто говорит, что это всё не нужно, и главное — писать код и красиво делать отчёты, но они лукавят. Чтобы обучить нейронку, нужна математика и формулы; чтобы найти закономерности в данных — нужна математика и статистика; чтобы сделать отчёт на основе большой выборки данных — ну, вы поняли. Математика рулит.
Знание машинного обучения. Работа дата-сайентиста — анализ данных огромного размера, и вручную это сделать нереально. Чтобы было проще, они поручают это компьютерам. Поручить такую задачу — значит настроить готовую нейросеть или обучить свою. Поручить программисту обычно это нельзя — слишком много нужно будет объяснить и проконтролировать.
Программирование на Python и R. Мы уже писали, что Python — идеальный язык для машинного обучения и нейросетей. На нём можно быстро написать любую модель для первоначальной оценки гипотезы, поиска общих данных или простой аналитики.
R — язык программирования для статического анализа. Если вам нужно прикинуть, как лайки на странице зависят от количества просмотров или до какого места читатель гарантированно долистывает статью (чтобы поставить туда баннер), — R вам поможет. Но если вы не знаете математику — не поможет.
 R и статистика в действии. Картинка с Хабра.
R и статистика в действии. Картинка с Хабра.
Умение получать и визуализировать данные. Не всем дата-сайентистам везёт настолько, что они сразу получают готовые наборы данных для обработки. Чаще всего они сами должны выяснить, где, откуда, как и сколько брать данных. Здесь обычные программисты им уже могут помочь — спарсить сайт, выкачать большую базу данных или настроить сбор статистики на сервере.
Второй важный навык в этой профессии — умение наглядно показать результаты работы. Какой толк в графиках, если никто, кроме автора, не понимает, что там нарисовано? Задача дата-сайентиста — представить данные наглядным образом, чтобы зрителю было легче сделать нужный вывод.
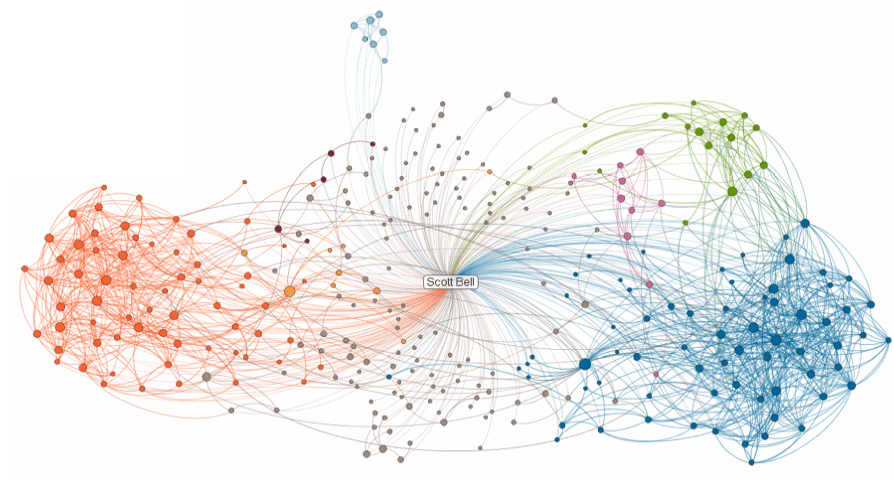 Связи в твиттере некоего Скотта Белла. Явно видны несколько разных групп фолловеров, которые мало пересекаются между собой. Это и есть наглядное представление данных.
Связи в твиттере некоего Скотта Белла. Явно видны несколько разных групп фолловеров, которые мало пересекаются между собой. Это и есть наглядное представление данных.
Хорошие конференции и митапы
International Conference on Big Data and its Applications (ICBDA)
- Самая серьезная конференция по Big Data на русском языке/li>
- Участвуют представители бизнеса, научные сотрудники, ученые и создатели новых технологий
- Включает соревнования, научный семинар, выставку
- Крупнейшая международная конференция, которая сегодня проводится в крупнейших технологических центрах, таких как Сан-Хосе,Нью-Йорк, Лондон и другие
- Все звезды и все новинки — здесь
- Кроме конференции проводятся воркшопы и обучение, возможно также онлайн-участие
- Ежегодный фестиваль и IT-форум, посвященный анализу данных, проходящий в Москве
- Для профессионалов в области Big Data и новичков в этой сфере
- Большие данные, искусственный интеллект, глубинное обучение, множество бизнес-кейсов
- Ежегодная конференция по Data Science, проходящая раз в год в Москве
- Для разработчиков, инженеров, исследователей
- Кейсы, на примере которых наглядно показывается, почему не стоит забивать гвозди микроскопом
- Одно из самых крупных и живых сообществ по анализу данных в рунете
- В основе — групповой чат Slack
- Здесь можно проконсультироваться, узнать о новых технологиях, найти работу и найти data scientist’а
- Группа, посвященная митапам по Data Science в Москве
- Анонсы встреч, лекций, мастер-классов, выступлений, обсуждений — все на тему Data Science
- Для людей, занимающихся и интересующихся анализом, визуализацией данных и майнингом
Что такое Data Science?
Вообще говоря, Data Science — это набор конкретных дисциплин из разных направлений, отвечающих за анализ данных и поиск оптимальных решений на их основе. Раньше этим занималась только математическая статистика, затем начали использовать машинное обучение и искусственный интеллект, которые в качестве методов анализа данных к матстатистике добавили оптимизацию и computer science (то есть информатику, но в более широком смысле, чем это принято понимать в России).
Основная статья — Наука о данных (Data Science)
А чем занимаются ученые из этой сферы?
Во-первых, программированием, математическими моделями и статистикой. Но не только
Для них очень важно разбираться в том, что происходит в предметной области (например, в финансовых процессах, биоинформатике, банковском деле или даже в компьютерной игре), чтобы отвечать на реальные вопросы: какие риски сопровождают ту или иную компанию, какие наборы генов соответствуют определенному заболеванию, как распознать мошеннические транзакции или какое поведение людей соответствует игрокам, которых надо забанить.
Полный курс по Data Science
Длительность: 18 месяцев, Около 8 часов в неделюФормат: занятия в записи, проверяют дз, есть общий чат и по выходным проводят вебинары с ответами на вопросыОсобенности: Школа специализируется на аналитике и разработке
Полная стоимость: 162 000₽/курс
Стоимость в рассрочку: от 4 500₽/месПрограмма курса
Ступеньки карьеры и перспективы
Профессия Data Scientist сама по себе является высоким достижением, для которой требуются серьёзные теоретические знания и практический опыт нескольких профессий. В любой организации такой специалист является ключевой фигурой. Чтобы достичь этой высоты надо упорно и целенаправленно работать и постоянно совершенствоваться во всех сферах, составляющих основу профессии.
Интересные факты о профессии
Про Data Scientist шутят: это универсал, который программирует лучше любого специалиста по статистике, и знает статистику лучше любого программиста. А в бизнес-процессах разбирается лучше руководителя компании.
ЧТО ТАКОЕ «BIGDATA» в реальных цифрах?
- Через каждые 2 дня объём данных увеличивается на такое количество информации, которое было создано человечеством от Рождества Христова до 2003 г.
- 90% всех существующих на сегодня данных появились за последние 2 года.
- До 2020 г. объём информации увеличится от 3,2 до 40 зеттабайт. 1 зеттабайт = 10 21 байт.
- В течение 1 минуты в сети Facebook загружается 200 тысяч фото, отправляется 205 млн. писем, выставляется 1,8 млн. лайков.
- В течение 1 секунды Google обрабатывает 40 тыс. поисковых запросов.
- Каждые 1,2 года удваивается общий объём данных в каждой отрасли.
- К 2020 г. объём рынка Hadoop-сервисов вырастет до $50 млрд.
- В США в 2015 г. создано 1,9 млн. рабочих мест для специалистов, работающих на проектах Big Data.
- Технологии Big Data увеличивают прибыль торговых сетей на 60% в год.
- По прогнозам объём рынка Big Data увеличится до $68,7 млрд. в 2020 г. по сравнению с $28,5 млрд. в 2014 г.
Несмотря на такие позитивные показатели роста, бывают и ошибки в прогнозах. Так, например, одна из самых громких ошибок 2016 года: не сбылись прогнозы по поводу выборов президента США. Прогнозы были представлены знаменитыми Data Scientist США Нейт Сильвером, Керк Борном и Биллом Шмарзо в пользу Хиллари Клинтон. В прошлые предвыборные компании они давали точные прогнозы и ни разу не ошибались.
В этом году Нейт Сильвер, например, дал точный прогноз для 41 штата, но для 9 штатов — ошибся, что и привело к победе Трампа. Проанализировав причины ошибок 2016 года, они пришли к выводу, что:
- Математические модели объективно отражают картину в момент их создания. Но они имеют период полураспада, к концу которого ситуация может кардинально измениться. Прогнозные качества модели со временем ухудшаются. В данном случае, например, сыграли свою роль должностные преступления, неравенство доходов и другие социальные потрясения. Поэтому модель необходимо регулярно корректировать с учётом новых данных. Это не было сделано.
- Необходимо искать и учитывать дополнительные данные, которые могут оказать существенное влияние на прогнозы. Так, при просмотре видео митингов в предвыборной кампании Клинтон и Трампа, не было учтено общее количество участников митингов. Речь шла приблизительно о сотнях человек. Оказалось, что в пользу Трампа на митинге присутствовало 400-600 человек в каждом, а в пользу Клинтон — всего 150-200, что и отразилось на результатах.
- Математические модели в предвыборных кампаниях основаны на демографических данных: возраст, раса, пол, доходы, статус в обществе и т.п. Вес каждой группы определяется тем, как они голосовали на прошлых выборах. Такой прогноз имеет погрешность 3-4 % и работает достоверно при большом разрыве между кандидатами. Но в данном случае разрыв между Клинтон и Трампом был небольшим, и эта погрешность оказала существенное влияние на результаты выборов.
- Не было учтено иррациональное поведение людей. Проведенные опросы общественного мнения создают иллюзию, что люди проголосуют так, как ответили в опросах. Но иногда они поступают противоположным образом. В данном случае следовало бы дополнительно провести аналитику лица и речи, чтобы выявить недобросовестное отношение к голосованию.
В целом, ошибочный прогноз оказался таковым по причине небольшого разрыва между кандидатами. В случае большого разрыва эти погрешности не имели бы такого решающего значения.