35 бесплатных онлайн-курсов по data science и аналитике данных
Содержание:
- Что нужно, чтобы стать специалистом?
- Рынок Big data в России
- Какие компании занимаются большими данными
- Зачем использовать Kubernetes для работы с Big Data
- Рынок технологий больших данных в России и мире
- Что должен знать Data Engineer
- What is big data analytics?
- Как стать аналитиком данных и где этому учат
- Перспективы и тенденции развития Big data
- Big Data Industry Applications
- История появления и развития Big Data
- Как устроены фабрики данных: Big Data и не только
- Что такое Big data?
- Manufacturing and Natural Resources
- Salary Trends
- Чем отличается аналитик Big Data от исследователя данных
- Different Types of Big Data Analytics
- The big benefits of big data analytics
- Какие используются инструменты и технологии big data
- Как стать Data Engineer и куда расти
Что нужно, чтобы стать специалистом?
Необходима сильная теоретическая база. Онлайн-курсы включают основы статистики, высшей математики, необходимую теорию и практические задания.
После освоения базы рекомендуется читать научно-техническую и научно-популярную литературу по теме, а также смотреть специализированные Youtube-каналы и слушать подкасты. Это позволит быть в курсе последних новостей Big Data.
Обучение должно проходить ежедневно, минимум 3-4 часа. Обязательно нужно закреплять полученные знания на практике с помощью онлайн-курсов (где будет помогать личный помощник-куратор) и популярных ресурсов (самостоятельно).
Рынок Big data в России
В 2017 году мировой доход на рынке big data должен достигнуть $150,8 млрд, что на 12,4% больше, чем в прошлом году. В мировом масштабе российский рынок услуг и технологий big data ещё очень мал. В 2014 году американская компания IDC оценивала его в $340 млн. В России технологию используют в банковской сфере, энергетике, логистике, государственном секторе, телекоме и промышленности.
Что касается рынка данных, он в России только зарождается. Внутри экосистемы RTB поставщиками данных выступают владельцы программатик-платформ управления данными (DMP) и бирж данных (data exchange). Телеком-операторы в пилотном режиме делятся с банками потребительской информацией о потенциальных заёмщиках.
|
15 сентября в Москве состоится конференция по большим данным Big Data Conference. В программе — бизнес-кейсы, технические решения и научные достижения лучших специалистов в этой области. Приглашаем всех, кто заинтересован в работе с большими данными и хочет их применять в реальном бизнесе. |
Обычно большие данные поступают из трёх источников:
- Интернет (соцсети, форумы, блоги, СМИ и другие сайты);
- Корпоративные архивы документов;
- Показания датчиков, приборов и других устройств.
Какие компании занимаются большими данными
Первыми с большими данными, либо с «биг дата», начали работать сотовые операторы и поисковые системы. У поисковиков становилось все больше и больше запросов, а текст тяжелее, чем цифры. На работу с абзацем текста уходит больше времени, чем с финансовой транзакцией. Пользователь ждет, что поисковик отработает запрос за долю секунды — недопустимо, чтобы он работал даже полминуты. Поэтому поисковики первые начали работать с распараллеливанием при работе с данными.
Чуть позже подключились различные финансовые организации и ритейл. Сами транзакции у них не такие объемные, но большие данные появляются за счет того, что транзакций очень много.
Количество данных растет вообще у всех. Например, у банков и раньше было много данных, но для них не всегда требовались принципы работы, как с большими. Затем банки стали больше работать с данными клиентов. Стали придумывать более гибкие вклады, кредиты, разные тарифы, стали плотнее анализировать транзакции. Для этого уже требовались быстрые способы работы.
Сейчас банки хотят анализировать не только внутреннюю информацию, но и стороннюю. Они хотят получать большие данные от того же ритейла, хотят знать, на что человек тратит деньги. На основе этой информации они пытаются делать коммерческие предложения.
Сейчас вся информация связывается между собой. Ритейлу, банкам, операторам связи и даже поисковикам — всем теперь интересны данные друг друга.
Зачем использовать Kubernetes для работы с Big Data
Главные преимущества работы с Big Data в Kubernetes — он позволяет построить гибкую автомасштабируемую систему и изолировать рабочие среды для обработки данных, обучения и тестирования моделей. Но самостоятельная установка и обслуживание кластера — нетривиальная задача. Kubernetes удобно арендовать в облаке, потому что кластер можно развернуть за несколько минут, а облачный провайдер предоставляет практически неограниченные ресурсы. Также он возьмет на себя задачи обслуживания: интеграцию новых сервисов, обновление кластера, поддержка и тому подобное. Наконец, облачная инсталляция предполагает большую экономическую эффективность за счёт схемы pay-as-you-go на фоне меняющихся нагрузок.
Cloud-Native подход к работе с большими данными позволяет избавиться от проблем классического Hadoop-кластера, а также получить больше возможностей от других инструментов. На облачных платформах есть разные сервисы, которые помогают в работе с Big Data: объектное хранилище S3, Hadoop aaS, вычисления на базе GPU и другие.
Рынок технологий больших данных в России и мире
По данным на 2014 год 40% объема рынка больших данных составляют сервисные услуги. Немного уступает (38%) данному показателю выручка от использования Big Data в компьютерном оборудовании. Оставшиеся 22% приходятся на долю программного обеспечения.
Наиболее полезные в мировом сегменте продукты для решения проблем Big Data, согласно статистическим данным, – аналитические платформы In-memory и NoSQL . 15 и 12 процентов рынка соответственно занимают аналитическое ПО Log-file и платформы Columnar. А вот Hadoop/MapReduce на практике справляются с проблемами больших данных не слишком эффективно.
Результаты внедрения технологий больших данных:
- рост качества клиентского сервиса;
- оптимизация интеграции в цепи поставок;
- оптимизация планирования организации;
- ускорение взаимодействия с клиентами;
- повышение эффективности обработки запросов клиентов;
- снижение затрат на сервис;
- оптимизация обработки клиентских заявок.
Что должен знать Data Engineer
-
Структуры и алгоритмы данных;
-
Особенности хранения информации в SQL и NoSQL базах данных. Наиболее распространённые: MySQL, PostgreSQL, MongoDB, Oracle, HP Vertica, Amazon Redshift;
-
ETL-системы (BM WebSphere DataStage; Informatica PowerCenter; Oracle Data Integrator; SAP Data Services; SAS Data Integration Server);
-
Облачные сервисы для больших данных Amazon Web Services, Google Cloud Platform, Microsoft Azure;
-
Кластеры больших данных на базе Apache и SQL-движки для анализа данных;
-
Желательно знать языки программирования (Python, Scala, Java).
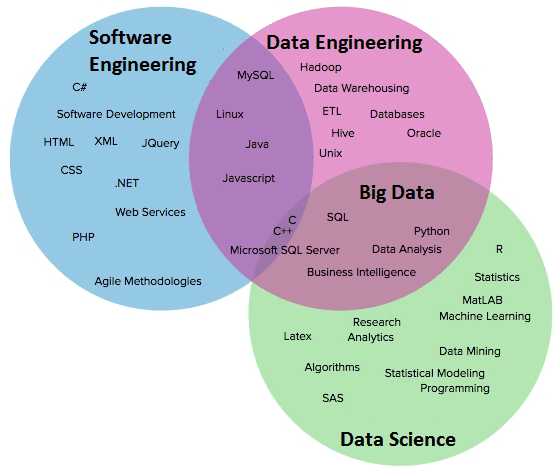
Стек умений и навыков инженера больших данных частично пересекается с дата-сайентистом, но в проектах они, скорее, дополняют друг друга.
Data Engineer сильнее в программировании, чем дата-сайентист. А тот, в свою очередь, сильнее в статистике. Сайентист способен разработать модель-прототип обработки данных, а инженер — качественно воплотить её в реальность и превратить код в продукт, который затем будет решать конкретные задачи.
Инженеру не нужны знания в Business Intelligence, а вот опыт разработки программного обеспечения и администрирования кластеров придётся как раз кстати.
Но, несмотря на то что Data Engineer и Data Scientist должны работать в команде, у них бывают конфликты. Ведь сайентист — это по сути потребитель данных, которые предоставляет инженер. И грамотно налаженная коммуникация между ними — залог успешности проекта в целом.
Плюсы и минусы профессии инженера больших данных
Плюсы:
-
Отрасль в целом и специальность в частности ещё очень молоды. Особенно в России и странах СНГ. Востребованность специалистов по BDE стабильно растёт, появляется всё больше проектов, для которых нужен именно инженер больших данных. На hh.ru, по состоянию на начало апреля, имеется 768 вакансий.
-
Пока что конкуренция на позиции Big Data Engineer в разы ниже, чем у Data Scientist. Для специалистов с опытом в разработке сейчас наиболее благоприятное время, чтобы перейти в специальность. Для изучения профессии с нуля или почти с нуля — тоже вполне хорошо (при должном старании). Тенденция роста рынка в целом будет продолжаться ближайшие несколько лет, и всё это время будет дефицит хороших спецов.
-
Задачи довольно разнообразные — рутина здесь есть, но её довольно немного. В большинстве случаев придётся проявлять изобретательность и применять творческий подход. Любителям экспериментировать тут настоящее раздолье.
Минусы
-
Большое многообразие инструментов и фреймворков. Действительно очень большое — и при подготовке к выполнению задачи приходится серьёзно анализировать преимущества и недостатки в каждом конкретном случае. А для этого нужно довольно глубоко знать возможности каждого из них. Да-да, именно каждого, а не одного или нескольких.
Уже сейчас есть целых шесть платформ, которые распространены в большинстве проектов.
Spark — популярный инструмент с богатой экосистемой и либами, для распределенных вычислений, который может использоваться для пакетных и потоковых приложений. Flink — альтернатива Spark с унифицированным подходом к потоковым/пакетным вычислениям, получила широкую известность в сообществе разработчиков данных. Kafka — сейчас уже полноценная потоковая платформа, способная выполнять аналитику в реальном времени и обрабатывать данные с высокой пропускной способностью. ElasticSearch — распределенный поисковый движок, построенный на основе Apache Lucene. PostgreSQL — популярная бд с открытым исходным кодом. Redshift — аналитическое решение для баз/хранилищ данных от AWS.
-
Без бэкграунда в разработке ворваться в BD Engineering сложно. Подобные кейсы есть, но основу профессии составляют спецы с опытом разработки от 1–2 лет. Да и уверенное владение Python или Scala уже на старте — это мастхэв.
-
Работа такого инженера во многом невидима. Его решения лежат в основе работы других специалистов, но при этом не направлены прямо на потребителя. Их потребитель — это Data Scientist и Data Analyst, из-за чего бывает, что инженера недооценивают. А уж изменить реальное и объективное влияние на конечный продукт и вовсе практически невозможно. Но это вполне компенсируется высокой зарплатой.
What is big data analytics?
Big data analytics describes the process of uncovering trends, patterns, and correlations in large amounts of raw data to help make data-informed decisions. These processes use familiar statistical analysis techniques—like clustering and regression—and apply them to more extensive datasets with the help of newer tools. Big data has been a buzz word since the early 2000s, when software and hardware capabilities made it possible for organizations to handle large amounts of unstructured data. Since then, new technologies—from Amazon to smartphones—have contributed even more to the substantial amounts of data available to organizations. With the explosion of data, early innovation projects like Hadoop, Spark, and NoSQL databases were created for the storage and processing of big data. This field continues to evolve as data engineers look for ways to integrate the vast amounts of complex information created by sensors, networks, transactions, smart devices, web usage, and more. Even now, big data analytics methods are being used with emerging technologies, like machine learning, to discover and scale more complex insights.
Как стать аналитиком данных и где этому учат
67% специалистов по аналитике пришли в Data Science из других сфер. В основном это разработчики и маркетологи, но есть и неожиданные профессиональные бэкграунды: геммологи, звукорежиссеры и даже ядерные физики.
Чаще всего изучать аналитику начинают с профессиональной литературы, тематических статей, авторитетных блогов и профильных каналов в мессенджерах. В открытом доступе много теоретической информации, где можно собрать базовый пул теории и практики. И все же для первых самостоятельных шагов нужна система. Проще и быстрее погрузиться в практическую аналитику на образовательных курсах.
Роман Крапивинруководитель проектов, компания ООО «ИНТЭК»:
«В 2020 я задумался о смене профессии, поскольку пандемия коронавируса серьезно ударила по строительному бизнесу, где я работал руководителем проектов последние три года. Долго выбирал онлайн-курсы, хотел прокачать свои скилы в проектном управлении и пошел на курс Project Manager.
Поэтому я начал изучать Power BI, на котором научился визуализировать данные и получил первые знания для дальнейшей работы с аналитическими данными. Но тогда я понял, что для меня мало базовых основ аналитики. Поэтому для себя я открыл профессию Аналитик BI. И в настоящее время изучаю программу визуализации данных Tableau, программу для работы с базами данных SQL, прошел курс по аналитике больших данных (Big Data). К сожалению, на настоящем месте работы я не могу в полной мере применять аналитические знания и программы, которые я освоил. Поэтому задумался о смене профессии: хотел бы попробовать себя в финансовом секторе или крупном ритейле, чтобы погрузиться в мир аналитики».
Иван Натаровконсультант отдела развития предпринимательства Министерства экономического развития Приморского края:
«Будучи студентом магистратуры, проводил исследование инновационной экосистемы Приморского края, тогда познакомился с нейросетями и Data Science. Суть исследования заключалась в разработке алгоритма, основанного на нейросетях и теории нечеткого множества и нечеткой логики, который позволял бы давать объективную оценку инновационного развития региона. У нас это получилось, даже научную статью написали.
Параллельно я изучал Data Science и посетил форум «Открытые инновации» в 2019 году. Послушав экспертов, я понял, что влюбился в эту сферу.
Я люблю узнавать истории из данных, поэтому и выбрал направление аналитики данных.
Я все еще учусь, но почти за год прокачался в этом направлении довольно неплохо. Из инструментов, что я изучил, любимыми стали Python и Power BI, они смогли автоматизировать многие процессы в работе, активно чекаю их. Python больше использую для написания парсеров XML и HTML, Power BI — для предобработки данных и визуализации».
Перспективы и тенденции развития Big data
В 2017 году, когда большие данные перестали быть чем-то новым и неизведанным, их важность не только не уменьшилась, а еще более возросла. Теперь эксперты делают ставки на то, что анализ больших объемов данных станет доступным не только для организаций-гигантов, но и для представителей малого и среднего бизнеса
Такой подход планируется реализовать с помощью следующих составляющих:
Облачные хранилища
Хранение и обработка данных становятся более быстрыми и экономичными – по сравнению с расходами на содержание собственного дата-центра и возможное расширение персонала аренда облака представляется гораздо более дешевой альтернативой.
Использование Dark Data
Так называемые «темные данные» – вся неоцифрованная информация о компании, которая не играет ключевой роли при непосредственном ее использовании, но может послужить причиной для перехода на новый формат хранения сведений.
Искусственный интеллект и Deep Learning
Технология обучения машинного интеллекта, подражающая структуре и работе человеческого мозга, как нельзя лучше подходит для обработки большого объема постоянно меняющейся информации. В этом случае машина сделает все то же самое, что должен был бы сделать человек, но при этом вероятность ошибки значительно снижается.
Blockchain
Эта технология позволяет ускорить и упростить многочисленные интернет-транзакции, в том числе международные. Еще один плюс Блокчейна в том, что благодаря ему снижаются затраты на проведение транзакций.
Самообслуживание и снижение цен
В 2017 году планируется внедрить «платформы самообслуживания» – это бесплатные площадки, где представители малого и среднего бизнеса смогут самостоятельно оценить хранящиеся у них данные и систематизировать их.
Big Data Industry Applications
Here are some of the sectors where Big Data is actively used:
- Ecommerce — Predicting customer trends and optimizing prices are a few of the ways e-commerce uses Big Data analytics
- Marketing — Big Data analytics helps to drive high ROI marketing campaigns, which result in improved sales
- Education — Used to develop new and improve existing courses based on market requirements
- Healthcare — With the help of a patient’s medical history, Big Data analytics is used to predict how likely they are to have health issues
- Media and entertainment — Used to understand the demand of shows, movies, songs, and more to deliver a personalized recommendation list to its users
- Banking — Customer income and spending patterns help to predict the likelihood of choosing various banking offers, like loans and credit cards
- Telecommunications — Used to forecast network capacity and improve customer experience
- Government — Big Data analytics helps governments in law enforcement, among other things
История появления и развития Big Data
Впервые термин «большие данные» появился в прессе в 2008 году, когда редактор журнала Nature Клиффорд Линч выпустил статью на тему развития будущего науки с помощью технологий работы с большим количеством данных. До 2009 года данный термин рассматривался только с точки зрения научного анализа, но после выхода еще нескольких статей пресса стала широко использовать понятие Big Data – и продолжает использовать его в настоящее время.
В 2010 году стали появляться первые попытки решить нарастающую проблему больших данных. Были выпущены программные продукты, действие которых было направлено на то, чтобы минимизировать риски при использовании огромных информационных массивов.
К 2011 году большими данными заинтересовались такие крупные компании, как Microsoft, Oracle, EMC и IBM – они стали первыми использовать наработки Big data в своих стратегиях развития, причем довольно успешно.
ВУЗы начали проводить изучение больших данных в качестве отдельного предмета уже в 2013 году – теперь проблемами в этой сфере занимаются не только науки о данных, но и инженерия вкупе с вычислительными предметами.
Как устроены фабрики данных: Big Data и не только
На текущий момент фабрика данных – это тренд в области Big Data и корпоративного ИТ-сектора, а не готовые технологические решения. На практике сегодня для сквозной интеграции и ETL/ELT-процессов используется вся мощь технологий Big Data: Apache Kafka, Spark, Hadoop, Hive, NiFi, AirFlow и прочие средства для сбора, обработки, маршрутизации и преобразования пакетных и потоковых данных в различных форматах.
Помимо упомянутых и других инструментов Big Data, а также базовых положений DataOps, концепция Data Fabric еще дополнена семантическими графами, которые позволяют определять, стандартизировать и согласовывать значение всех входящих данных в бизнес-терминах, понятных для конечных пользователей . Примечательно, что графовую аналитику Gartner также относит к наиболее перспективным трендам 2020 года .
Наконец, фабрика данных по максимуму использует весь потенциал облачных технологий, виртуализируя все компоненты ИТ-инфраструктуры, от наборов информации до программных приложений . Подобная сервисная модель соответствует DevOps-подходу, а потому инструменты контейнеризации (Docker, Kubernetes) также относятся к средствам Data Fabric.
Таким образом, для развертывания уникальной фабрики данных, а также создания непрерывных конвейеров автоматического сбора и обработки информационных пакетов и потоков необходимы совместные усилия всех профильных ИТ-специалистов по большим данным. Потребуется целая команда администраторов Data Lakes, локальных и облачных кластеров, разработчиков распределенных приложений, инженеров и аналитиков данных, а также специалистов по методам Machine Learning.
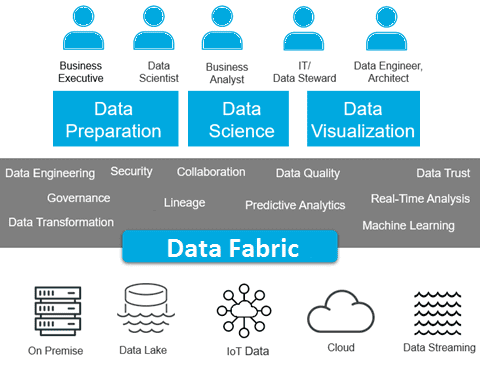
Пользователи и ключевые черты фабрики больших данных
Подробнее о том, как организовать собственную Data Fabric для цифровизации своих бизнес-процессов и аналитики больших данных, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Аналитика больших данных для руководителей
Смотреть расписание
Записаться на курс
Источники
- https://www.gartner.com/smarterwithgartner/gartner-top-10-data-analytics-trends/
- https://docs.microsoft.com/ru-ru/azure/data-factory/frequently-asked-questions
- https://www.gartner.com/en/newsroom/press-releases/2019-02-18-gartner-identifies-top-10-data-and-analytics-technolo
- https://hightech.plus/2018/11/26/kak-rabotayut-kitaiskie-fabriki-dannih-gde-treniruyut-ii
- https://www.computerweekly.com/blog/Data-Matters/The-Enterprise-Data-Fabric-an-information-architecture-for-our-times
- https://tdwi.org/articles/2018/06/20/ta-all-data-fabrics-for-big-data.aspx
- https://www.itweek.ru/bigdata/article/detail.php?ID=210273
- https://blog.cloudera.com/conquering-hybrid-and-multi-cloud-with-big-data-fabric/
Что такое Big data?
Большие данные — технология обработки информации, которая превосходит сотни терабайт и со временем растет в геометрической прогрессии.
Такие данные настолько велики и сложны, что ни один из традиционных инструментов управления данными не может их хранить или эффективно обрабатывать. Проанализировать этот объем человек не способен. Для этого разработаны специальные алгоритмы, которые после анализа больших данных дают человеку понятные результаты.
В Big Data входят петабайты (1024 терабайта) или эксабайты (1024 петабайта) информации, из которых состоят миллиарды или триллионы записей миллионов людей и все из разных источников (Интернет, продажи, контакт-центр, социальные сети, мобильные устройства). Как правило, информация слабо структурирована и часто неполная и недоступная.
Manufacturing and Natural Resources
Industry-specific Big Data Challenges
Increasing demand for natural resources, including oil, agricultural products, minerals, gas, metals, and so on, has led to an increase in the volume, complexity, and velocity of data that is a challenge to handle.
Similarly, large volumes of data from the manufacturing industry are untapped. The underutilization of this information prevents the improved quality of products, energy efficiency, reliability, and better profit margins.
Applications of Big Data in Manufacturing and Natural Resources
In the natural resources industry, Big Data allows for predictive modeling to support decision making that has been utilized for ingesting and integrating large amounts of data from geospatial data, graphical data, text, and temporal data. Areas of interest where this has been used include; seismic interpretation and reservoir characterization.
Big data has also been used in solving today’s manufacturing challenges and to gain a competitive advantage, among other benefits.
In the graphic below, a study by Deloitte shows the use of supply chain capabilities from Big Data currently in use and their expected use in the future.
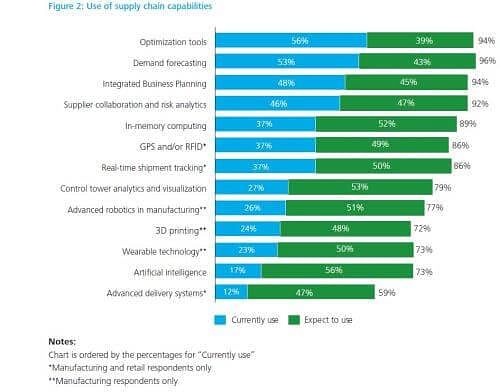
Source: Supply Chain Talent of the Future
Big Data Providers in this industry include CSC, Aspen Technology, Invensys, and Pentaho.
Salary Trends
Although they are in the same domain, each of these professionals—data scientists, big data specialists, and data analysts—earn varied salaries.
FREE Course: Introduction to Data Analytics
Learn Data Analytics Concepts, Tools & SkillsStart Learning
Big Data Specialist Salary
According to Glassdoor, the average base salary for a big data specialist is $103,000 per year.
| Looking forward to becoming a Data Scientist? Check out the Data Scientist Course and get certified today. |
Data Analyst Salary
According to Glassdoor, the average base salary for a data analyst is $62,453 per year.
Of course, these are just averages and will vary based on several factors. Many professionals earn—or have the potential to earn—higher salaries with the right qualifications.
No matter which path you ultimately decide to take, Simplilearn has dozens of data science, big data, and data analytics courses available online. If you’d like to become an expert in data science, data analytics or big data, check out our Post Graduate program in Data Science, Data Analytics, and Data Engineering.
Чем отличается аналитик Big Data от исследователя данных
На первый взгляд может показаться, что Data Scientist ничем не отличается от Data Analyst, ведь их рабочие обязанности и профессиональные компетенции частично пересекаются. Однако, это не совсем взаимозаменяемые специальности. При значительном сходстве, отличия между ними также весьма существенные:
- по инструментарию – аналитик чаще всего работает с ETL-хранилищами и витринами данных, тогда как исследователь взаимодействует с Big Data системами хранения и обработки информации (стек Apache Hadoop, NoSQL-базы данных и т.д.), а также статистическими пакетами (R-studio, Matlab и пр.);
- по методам исследований – Data Analyst чаще использует методы системного анализа и бизнес-аналитики, тогда как Data Scientist, в основном, работает с математическими средствами Computer Science (модели и алгоритмы машинного обучения, а также другие разделы искусственного интеллекта);
- по зарплате – на рынке труда Data Scientist стоит чуть выше, чем Data Analyst (100-200 т.р. против 80-150 т.р., по данным рекрутингового портала HeadHunter в августе 2019 г.). Возможно, это связано с более высоким порогом входа в профессию: исследователь по данным обладает навыками программирования, тогда как Data Analyst, в основном, работает с уже готовыми SQL/ETL-средствами.
На практике в некоторых компаниях всю работу по данным, включая бизнес-аналитику и построение моделей Machine Learning выполняет один и тот же человек. Однако, в связи с популярностью T-модели компетенций ИТ-специалиста, при наличии широкого круга профессиональных знаний и умений предполагается экспертная концентрация в узкой предметной области. Поэтому сегодня все больше компаний стремятся разделять обязанности Data Analyst и Data Scientist, а также инженера по данным (Data Engineer) и администратора Big Data, о чем мы расскажем в следующих статьях.

Data Scientist – одна из самых востребованных профессий на современном ИТ-рынке
В области Big Data ученому по данным пригодятся практические знания по облачным вычислениям и инструментам машинного обучения. Эти и другие вопросы по исследованию данных мы рассматриваем на наших курсах обучения и повышения квалификации ИТ-специалистов в лицензированном учебном центре для руководителей, аналитиков, архитекторов, инженеров и исследователей Big Data в Москве:
- PYML: Машинное обучение на Python
- DPREP: Подготовка данных для Data Mining
- DSML: Машинное обучение в R
- DSAV: Анализ данных и визуализация в R
- AZURE: Машинное обучение на Microsoft Azure
Смотреть расписание
Записаться на курс
Different Types of Big Data Analytics
Here are the four types of Big Data analytics:
1. Descriptive Analytics
This summarizes past data into a form that people can easily read. This helps in creating reports, like a company’s revenue, profit, sales, and so on. Also, it helps in the tabulation of social media metrics. Use Case: The Dow Chemical Company analyzed its past data to increase facility utilization across its office and lab space. Using descriptive analytics, Dow was able to identify underutilized space. This space consolidation helped the company save nearly US $4 million annually.
2. Diagnostic Analytics
This is done to understand what caused a problem in the first place. Techniques like drill-down, data mining, and data recovery are all examples. Organizations use diagnostic analytics because they provide an in-depth insight into a particular problem.Use Case: An e-commerce company’s report shows that their sales have gone down, although customers are adding products to their carts. This can be due to various reasons like the form didn’t load correctly, the shipping fee is too high, or there are not enough payment options available. This is where you can use diagnostic analytics to find the reason.
3. Predictive Analytics
This type of analytics looks into the historical and present data to make predictions of the future. Predictive analytics uses data mining, AI, and machine learning to analyze current data and make predictions about the future. It works on predicting customer trends, market trends, and so on.Use Case: PayPal determines what kind of precautions they have to take to protect their clients against fraudulent transactions. Using predictive analytics, the company uses all the historical payment data and user behavior data and builds an algorithm that predicts fraudulent activities.
The big benefits of big data analytics
The ability to analyze more data at a faster rate can provide big benefits to an organization, allowing it to more efficiently use data to answer important questions. Big data analytics is important because it lets organizations use colossal amounts of data in multiple formats from multiple sources to identify opportunities and risks, helping organizations move quickly and improve their bottom lines. Some benefits of big data analytics include:
- Cost savings. Helping organizations identify ways to do business more efficiently
- Product development. Providing a better understanding of customer needs
- Market insights. Tracking purchase behavior and market trends
Read more about how real organizations reap the benefits of big data.
Какие используются инструменты и технологии big data
Поскольку данные хранятся на кластере, для работы с ними нужна особая инфраструктура. Самая популярная экосистема — это Hadoop. В ней может работать очень много разных систем: специальных библиотек, планировщиков, инструментов для машинного обучения и многого другое. Но в первую очередь эта система нужна, чтобы анализировать большие объемы данных за счет распределенных вычислений.
Например, мы ищем самый популярный твит среди данных разбитых на тысяче серверов. На одном сервере мы бы просто сделали таблицу и все. Здесь мы можем притащить все данные к себе и пересчитать. Но это не правильно, потому что очень долго.
Поэтому есть Hadoop с парадигмами Map Reduce и фреймворком Spark. Вместо того, чтобы тянуть данные к себе, они отправляют к этим данным участки программы. Работа идет параллельно, в тысячу потоков. Потом получается выборка из тысячи серверов на основе которой можно выбрать самый популярный твит.
Map Reduce более старая парадигма, Spark — новее. С его помощью достают данные из кластеров, и в нем же строят модели машинного обучения.
Как стать Data Engineer и куда расти
Профессия дата-инженера довольно требовательна к бэкграунду. Костяк профессии составляют разработчики на Python и Scala, которые решили уйти в Big Data. В русскоговорящих странах, к примеру, процент использования этих языков в работе с большими данными примерно 50/50. Если знаете Java — тоже хорошо.
Хорошее знание SQL тоже важно. Поэтому в Data Engineer часто попадают специалисты, которые уже ранее работали с данными: Data Analyst, Business Analyst, Data Scientist
Дата-сайентисту с опытом от 1–2 лет будет проще всего войти в специальность.
Фреймворками можно овладевать в процессе работы, но хотя бы несколько важно знать на хорошем уровне уже в самом начале.
Дальнейшее развитие для специалистов Big Data Engineers тоже довольно разнообразное. Можно уйти в смежные Data Science или Data Analytics, в архитектуру данных, Devops-специальности. Можно также уйти в чистую разработку на Python или Scala, но так делает довольно малый процент спецов.
Перспективы у профессии просто колоссальные. Согласно данным Dice Tech Job Report 2020, Data Engineering показывает невероятные темпы роста — в 2019 году рынок профессии увеличился на 50 %. Для сравнения: стандартным ростом считается 3–5 %.
В 2020 году темпы замедлились, но всё равно они многократно опережают другие отрасли. Спрос на специальность вырос ещё на 24,8 %. И подобные темпы сохранятся еще на протяжении минимум пяти лет.
Так что сейчас как раз просто шикарный момент, чтобы войти в профессию Data Engineering с нашим курсом Data Engineering и стать востребованным специалистом в любом серьёзном Data Science проекте. Пока рынок растёт настолько быстро, то возможность найти хорошую работу, есть даже у новичков.

Узнайте, как прокачаться и в других областях работы с данными или освоить их с нуля: